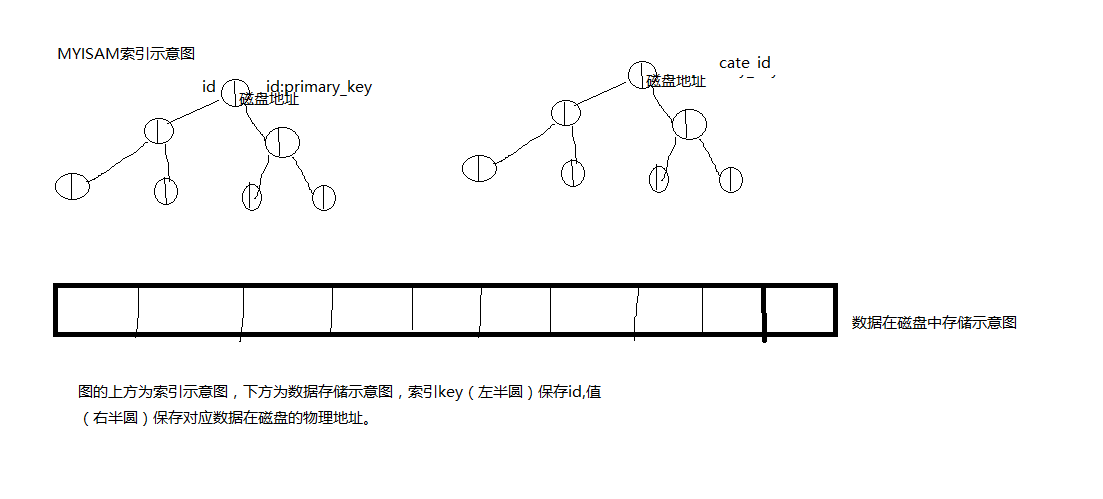
- mysql中innodb的索引:次索引指向对主索引的引用;
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
innodb的次索引保存索引键和主索引的id. - mysql中myisam索引:主索引和次索引都指向物理行;
参考文档:
参考文档:
1.打开/etc/security/limits.conf,在里面添加如下内容
其中*表示所有用户 nofile表示最大文件句柄数,表示能够打开的最大文件数目
2.编辑/etc/pam.d/common-session,添加如下内容
session required pam_limits.so
3.编辑/etc/profile,添加如下内容
ulimit -SHn 65535
然后重新启动机器,再利用ulimit -n查看文件句柄数,发现文件句柄数变为65535
http://xxxx.com/data/index (内部网站,不便透露地址)
缓慢原因分析:
网站优化,大多时候瓶颈都是出在mysql的查询上,特别是对于一些复杂的统计,当数据量大起来之后,各种连表,串库查询,更是如此。
所以,不用看代码,首先就来开启mysql的慢查询日志,果真发现了好几天查询巨慢的日志。慢sql如下:12345678910select p.reply_userid,p.reply_user,count(1) as askposts from j1_ask_threads t join j1_ask_posts p on t.tid=p.tid where p.rpid = 0 and p.status=1 `and p.reply_userid in(3554226,3554229) `and unix_timestamp(p.posttime) >= 1485878400 and unix_timestamp(p.posttime) < 1487692800 group by p.reply_userid order by askposts desc limit 0,75;
注意sql中着重的部分,该部分ids非常多,有差不多至少5000多个。真实的查询时间为:# Query_time: 38.5
总的数据量为: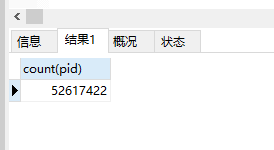
表结构:
用explain查看一下扫表行数和索引使用情况,发现扫表行数为:132032行。索引使用了rpid索引。
本sql主要的查询过滤条件为 reply_userid 因为这个字段用了5K之多的ids进行in查询操作。而从业务上分析,这个in操作又是不得不进行的。所以一开始,我把索引重心全都放到了reply_userid字段上。
而本查询刚好也用上了reply_userid。所以我放弃了对改sql索引方面的优化。转而进行从业务上进行修正。
业务熟悉:
从业务上看,本次操作的目的是:
1、从A库中的a表读取满足条件的用户,并取得这些用户的ids。
2、将拿到的ids到B库中的b表进行条件筛选。得到最终结果,再进行数据组装。
经过对业务的深入考察,初步出了两个方案。
方案一:(调整业务查询顺序)
由于步骤1查询到的数据量过大,再放入步骤2中查询,才导致查询过慢,那么如果可以把in查询中的ids数量减少,查询不就变快了吗?
所以,我想到的方案1是,先到B库中查询符合条件的数据。再把这些数据拿到A库中进行过滤,并得到最终结果。
方案二:
建一张统计表,按日统计数据,在符合条件的数据修改的接口处,把统计的数据汇总的统计表中,这是架构中最常规的做法,但是由于现在数据量已经上来了,系统涉及到的地方很多,这样做修改起来耗费的人力物力很多。所以该方案放到终极备用方案里面。
接下来就按照方案一的思路进行优化,发现效果并不明显,因为在第一步的操作中,虽然去除了in操作,但是其它字段也没用上索引啊!于是我考虑新建索引。我考虑到 posttime timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ‘回复时间’,
这一字段,发现每次筛选如果带上时间的话,再以这个时间为主,建立一个索引的话,可能速度会快上许多!因为索引的原理是在磁盘上按照建立的索引进行排序,把字段按顺序存储好。In查询之所以慢,是因为in里面的ids都是分散的,导致扫描的表会很多。而=,>,<操作不一样,是连续的。
但是,谁建的表:
时间不是应该用int型吗?常识!!!
我给大家看一下,为什么不要用timestamp,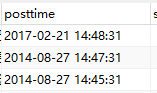
timestamp虽然底层也是整型,但是导致程序在进行查询的时候很麻烦,一般的程序员即使知道这里需要建立索引,他的程序也用不上。
看看我们原来是怎么做的。
这是最终的sql语句,
and unix_timestamp(p.posttime) >= 1485878400
and unix_timestamp(p.posttime) < 1487692800
这是原程序,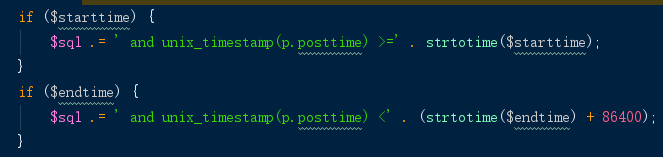
朋友们,看到了吗?
先把日期转换成时间戳,再跟mysql里面的字段进行对比,但是,mysql里imestamp类型的是日期格式的,所以也需要用内置函数unix_timestamp进行转换,结果,结果就是,我建了一万个索引,但是一个也没用上。
好了,说改就改,把程序对应的地方全部换成字符串日期格式,进行查询。对应sql是:
p.posttime >= 2017-02-14 18:19:23 and p.posttime < 2017-02-21 18:19:23
刷新页面,我靠,很遗憾!激动人心的时刻并没有到来。
报错了,sql语句错误,好吧,把sql复制到命令行直接执行,发现出错的地方主要是2017-02-14 18:19:23这个地方,我明白了,字符串加单引号的问题。
好了,怎么加单引号呢?
看php代码:12$start_date = '\'' . date('Y-m-d H:i:s', $starttime) . '\'';$end_date = '\'' . date('Y-m-d H:i:s', $endtime) . '\'';
很简单,转义就好了。
写到这里,再吐槽一下,为毛时间字段的设计有的地方又是int型呢?导致我改也得一个地方一个地方对照表看准了才能改啊!哥们,下次php程序设计模型的时候,时间字段请统一用int!谢谢!
改到后面,发现,方案一中原来没预料到的问题暴露出来了,什么问题呢?
1是分页问题;
2是逻辑修改的复杂程度。
所以,我决定git checkout回原来的代码,还是先走下原来的逻辑。
好了,随后的事情就是优化了下原来的代码结构,把冗余的代码剔除。
最后,我决定再加点料。综合所有与该表有关的查询,建立一个大家都用得上的组合索引。
KEY posttime (posttime,rpid,status,reply_userid) USING BTREE
这就是最后建好的索引,测试一下,好了,原来的38秒变成了现在的0.4秒,虽然从explain的结果上看,还没有优化到最优,因为还用了文件排序和临时表。
但是由于我们并没有冗余统计字段,所以,该部分已经没法进一步优化。
==============================我是华丽的分割线============================
#开启mysql的慢查询日志的方法:
###1、 登录mysql;
###2、 show variables like “%slow%”;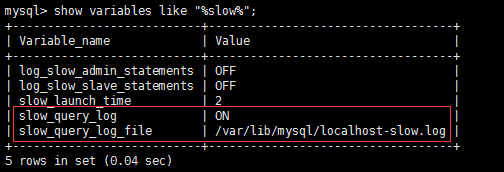
我的慢查询已经开启,慢查询日志位置为:/var/lib/mysql/localhost-slow.log
由于PHP对于异常的支持并没有JAVA等语言那么全面,导致很多初学者在写代码的过程中干脆不使用异常,很多情况下,这样做也不会产生什么问题,但在一些必要的场景下,这样做一方面程序上面会有瑕疵,另一方面,也暴露了自己菜鸟的特征,为了向高手靠近,我们有必要弄明白一下异常是个什么东东以及怎么使用异常这两个问题。
未答问题,先上代码!12<?phpthrow new Exception('Hello,Exception');
刷新浏览器,我们看到,一个丑陋的带着致命错误的页面出现在我们面前,页面内容如下:Fatal error: Uncaught exception 'Exception' with message 'Hello,Exception' in /www/test/exception2.php:2 Stack trace: #0 {main} thrown in /www/test/exception2.php on line 2
通过以上的hello,exception,我们可以知道两点:
|
|
我们在程序开始的时候把错误给屏蔽了,刷一下页面: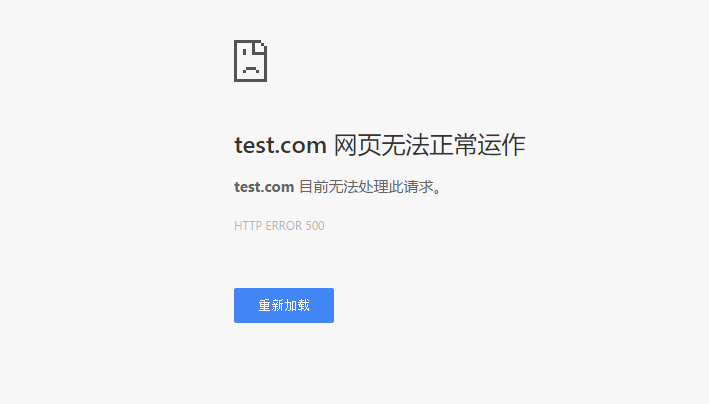
我靠!这是什么鬼!比刚才那个页面还要丑,提示我服务器500错误!
好吧,现在我们知道了,对于抛出的异常,必须进行捕获。好吧,来捕获一下吧!1234567<?phpini_set('display_errors', false);try{ throw new Exception('Hello,Exception');}catch(Exception $e){}
再次刷新页面,OK!一个干净的页面出现了,没错,什么也没有就对了。上面的代码中,我们用try语句,把异常进行了捕获,由于try语句后面必须跟上catch语句块,所以后面的catch语句块是不可省的,然后,就没有然后了,因为我们没有对捕获到的异常进行处理,所以,页面就什么都不显示。正常的开发中,肯定不能什么都不处理,那相当于你在大街上看见小偷把你妈妈的钱偷走了,而你却假装没看见一个样,所以,接下来,我们来处理一下刚才捕获的异常。1234567<?phpini_set('display_errors', false);try{ throw new Exception('Hello,Exception');}catch(Exception $e){ echo '妈妈,有小偷!';}
嗯,很好,刷一下页面,没错,现在就对了,看到小偷偷妈妈的钱要大胆的说出来!
如果程序中的每个异常都要亲自去处理,码农的命也太苦了!更重要的是,代码中到处都是try……catch……的异常捕获块,爱美的我受不鸟啊!幸运的是,我们有set_exception_handler函数。12345678910111213<?phpini_set('display_errors', false);set_exception_handler('handleException');throw new Exception('Hello,Exception');/** * 自定义异常处理句柄函数 * */function handleException($exception){ if ($exception instanceof ExitException) { return; } echo '<h1>妈妈,有小偷</h1>';}
现在我们有了健全的“自动抓小偷机制”,但是,对于我们自己写的代码,应该在哪些地方抛出异常来让我们的自动捕获机制捕获这些异常呢?
|
|
在没有任何异常的情况下,以上代码,塑造了一个平和的世界。大家都在快乐的生活。现在我们引入异常。123456789101112131415161718<?phpini_set('display_errors', false);set_exception_handler('handleException');echo '没有异常的时候,小熊快乐的生活'."<br>";echo '没有异常的时候,小羊快乐的生活'."<br>";echo '没有异常的时候,小呗快乐的生活'."<br>";throw new Exception('Hello,Exception');echo '没有异常的时候,小青快乐的生活'."<br>";echo '没有异常的时候,小年快乐的生活'."<br>";/** * 自定义异常处理句柄函数 * */function handleException($exception){ if ($exception instanceof ExitException) { return; } echo '<h1>'.$exception->getMessage().'</h1>';}
查看结果:
我们发现,默认情况下,出现异常,会中断当前执行的程序,而且后续代码也不执行了,为了避免这种情况,我们可以稍微优化一下:1234567891011121314151617181920212223<?phpini_set('display_errors', false);set_exception_handler('handleException');try{echo '没有异常的时候,小熊快乐的生活'."<br>";echo '没有异常的时候,小羊快乐的生活'."<br>"; throw new Exception('Hello,Exception');echo '没有异常的时候,小呗快乐的生活'."<br>";}catch(Exception $e){ echo 123; echo "<hr>";}echo '没有异常的时候,小青快乐的生活'."<br>";echo '没有异常的时候,小年快乐的生活'."<br>";/** * 自定义异常处理句柄函数 * */function handleException($exception){ if ($exception instanceof ExitException) { return; } echo '<h1>'.$exception->getMessage().'</h1>';}
查看输出:
我们可以看出,对于自己写的可能发生异常的代码,我们用try……catch……包起来,如果在catch语句块我们处理了异常,php会使用我们处理异常的逻辑,并且处理完之后,继续执行catch代码块之后的代码,如果不处理呢?123456789101112131415161718192021222324<?phpini_set('display_errors', false);set_exception_handler('handleException');try{echo '没有异常的时候,小熊快乐的生活'."<br>";echo '没有异常的时候,小羊快乐的生活'."<br>"; throw new Exception('Hello,Exception');echo '没有异常的时候,小呗快乐的生活'."<br>";}catch(Exception $e){ echo 123; echo "<hr>"; throw new Exception('还给你系统自己处理去');}echo '没有异常的时候,小青快乐的生活'."<br>";echo '没有异常的时候,小年快乐的生活'."<br>";/** * 自定义异常处理句柄函数 * */function handleException($exception){ if ($exception instanceof ExitException) { return; } echo '<h1>'.$exception->getMessage().'</h1>';}
查看输出:
我们发现,如果我们不手动处理异常,那么,程序就会调用我们的异常处理句柄函数来处理异常,并且程序终止于发生异常的地方,而如果我们对异常进行了处理,那么,程序将使用我们对异常处理的逻辑处理异常,并且继续往下执行程序。但是不管怎么样,try{语句块}语句块里面,异常发生之后的代码将再也没有机会执行。
终于到激动人心的时候了,通过上面对异常特点的研究,我们可以知道:
1、异常可以由程序员手动抛出;
2、程序员可以捕获异常,并对异常进行自行处理,或者再次抛出。
3、如果异常在程序中没有被处理,将会层层外抛,最终被我们设置的异常处理句柄函数所处理(如果注册了的话,没注册就会报服务器500错误)。
|
|
以上代码示例了利用抛出异常结合异常句柄函数美化类似网络连接出错等提示信息。对于这类一旦出错,程序没必要继续往下执行的异常,我们在主逻辑中只需要处理抛出异常即可。当然,对于生产环境,在抛出前,我们可以给管理员发短信提示一下。
对于MVC框架的PHP应用程序,由于PHP的返回值的单值。很多时候底层核心模块的封装,我们不仅需要返回错误码,还需要把错误的提示信息也返回给最终的控制器来处理。(当然,其实也可以不处理,依赖场景1中注册的句柄函数处理)
这里的事务包括但不限于数据库的事务,比如,一个常见的业务逻辑,用户上传一张图片,并把图片的地址记录到mysql中,这两件事也可以组成的事务,我们就可以配合异常机制,确保图片和记录同时被上传和被插入。1234567891011121314151617<?phpini_set('display_errors', false);set_exception_handler('handleException');class uploadException extends Exception{}class insertException extends Exception{}try{ //如果上传图片失败,抛出上传图片异常 //如果插入记录失败,抛出插入记录失败异常}catch(Exception $e){ //判断捕获的异常, //如果是上传图片异常,那么检查数据库中是否有对应的记录,有则删除 //如果是插入数据库记录异常,查看图片是否上传成功,成功则把图片删除}
看来写博客真的很不容易,收获也颇多,让自己思考了平时没注意到的许多问题并串成了线。希望自己能够坚持下去!加油!
工欲善其事,必先利其器。要想完全在Centos下存活,就得学会使用版本比较工具,命令行下,文件比较工具,我推荐vimdiff。前提是你已经配置好了vim。如果还没有,你可以查看配置vim这篇文章。已经配置好了,就可以继续打造 使用 vimdiff 来 git diff。
直接在命令行执行以下命令即可:
|
|
好了之后,我们使用 git d [文件名]打开对比代码,然后用 :wq 继续比较下一个文件。
很多人想要在linux下直接用vim开发,但是那个难受,除了快捷键之外的原因,我想,最难受的就是那色彩,眼睛完全无法接受。这篇博文主要是记录了为使用xshell的穷逼们快速打造一个看起来还不错的vim-ide。
看下效果先:
首先,xshell默认的配色是8位的,土黑色,很不好看,我们可以用命令tput colors查看:12[developer@localhost ~]$ tput colors8
一、修改/etc/profile 文件或者~/.bashrc文件,再最后面添加如下代码:12345if [ -e /usr/share/terminfo/x/xterm-256color ]; then export TERM='xterm-256color'else export TERM='xterm-color'fi
然后执行:
source /etc/profile
或者
source ~/.bashrc
让修改生效。
二、修改vim配置文件,让vim支持256位颜色。
打开~/.vim/vimrc文件,添加:
set t_Co=256
好了,执行tput colors看一下吧,如果输出256,表示配置生效,可以尽情的使用vim下的配色方案了。
还不会配置vim?使用 快速vim插件快速配置你自己的vim工作台吧!
推荐配色插件:
‘flazz/vim-colorschemes’
‘ueaner/molokai’
基础的掌握很多时候就像细节决定成败一样关键,它可遇看出一个人对知识积累的成都。由于入行是php。所以接触javascript是必须的,但深度总是不够,随着工作时间的增长,发现字符串这块在javascript中也是经常用到,因此做个积累,所谓积累,也就是遇到有用的就加进来。
|
|
该方法类似于php中的explode()函数,作用是将字符串按照分隔符separator进行切割,并返回一个数组。其中第二个参数howmany的作用是最多返回的数组长度。123var str = 'hello,world';var arr = str.split('');console.log(arr);
输出:["h", "e", "l", "l", "o", ",", "w", "o", "r", "l", "d"]
说到split,不得不说的就是逆向操作,Array.join(separator);
其中参数separator是用于拼接的分隔符,默认为’,’123var arr = ['hello','world','!'];var str = arr.join('-');console.log(str)
输出:hello-world-!
与上面两个搭配用的是数组的reverse()方法。
|
|
输出:dlrow,olleh
童年并不快乐,因此也不愿提起,希望每个小孩都有一个快乐的童年!
幼时过于压抑,致使高中极度叛逆,很多人的青春期都是叛逆的吧,只是有些人敢于表现出来,有些人一直把这种叛逆埋藏在心底罢了。
高考考了两次,然而,都是一样的,并没有什么长进。唯一长进的是,比以前更加大胆的叛逆了。
从这里开始,人与人之间的差距开始体现出来了。”选择大于努力!”很多事等你明白的时候已经没机会了,而有机会的时候却没眼光。所以说,眼界,见识很重要。农村的同学在选择的时候,大多都会比城里小孩吃亏。特别是完全由自己决策的时候。
选择师范专业,是人生中的第一个败笔,志愿直接决定了后面的努力方向。
不知道其它省份的师范大学是不是也一样学不到什么东西,反正我所就读的云南师范大学我是没在里面学到太多东西。说到这里很多人要站出来教我自学的重要性了。不可否认人应该有自学能力,但我想问问说这句话的人,诸位交学费进大学都是为了进去自学的么?大学让我觉得还有点用的就是让你可以认识一波人。你可以选择性交往一波志同道合的朋友。
荒废了的大学……,唯一值得庆幸的是,一直保留着对编程的热爱。
第二次选择,没有眼界的人,每次选择都是最糟糕的。因为你的选择很大程度取决于你周边的环境,你很可能会选择你的好友,亲戚、朋友他们最羡慕的东西,而这些他们羡慕的东西,只是他们眼中的极限。有可能他们穷其一生,都没有看到过整个省的全貌。所以,生命中影响你做决策的那些东西,生活环境,朋友都是很重要的东西。如果可以,尽可能多观察周围那些环境优越的人是做的什么选择。也许讲学习,他们比不上你,但是说到做决策,他们肯定有值的你学习的地方。有时候你会不明白他为什么要做那样的选择,并不重要,有可能他自己也不明白,但是大概率上来说,他所做的选择要优于你自己的决定。
第一份工作是到一个偏僻的小镇上当了几年教师。这份工作把我学生时代对教师的美好印象完全打破了。
我在这里每天看到的除了斗争还是斗争,越是贫瘠的地方,人与人之间的斗争方式也越是低级、直白。花了4年的时间,看到了很多无法用文明城市的手法解决的问题都在这种低级的斗争中解决了。不尽完美,却自有其平衡的生态。呆了4年的时间,并没有学会如何在这样的圈子生存,然而并不可惜。你是屠龙的刀,就不应该去杀鸡。比起杀鸡,杀鸡刀更有发言权。
离开之前,我得说一下这些年在这里除了本职工作以外的一些其它事情。因为这些事情与我能离开有着很大的关系。
上面的4年时光,无非是要提醒自己两件事:
1、想要得到东西,先尝试”失去”另外一些东西;
2、任何时候都不要把学习新东西的能力和自己的兴趣给丢了。
可以这么说,如果没有花钱购买到那套极有价值的教程,可能这一辈子就只能挣扎在那些”公人”(为了可以占便宜吃顿公家的饭而大打出手)的人群里面。所以说起来,机遇与知识这两种逆天换命的东西,前者可遇而不可求,遇上了,能不能抓住,看各人眼光;后者,只要认定是对自己确实有利的,花多少钱投资都是值得的。
云南达煜投资有限公司–这个公司是13-16年火上天的p2p(说白了就是互联网高利贷)公司。之所以说又一个第一份工作,是因为它可遇说成是更换职业后的第一份工作。这份工作持续的时间并不长,虽然只有短短1月的时间,却给我留下了永远抹不去的记忆。短短一月的成长,比起之前4年成长的还快许多。庆幸一开始遇到这样的公司,叹息最后公司留给我的失望和伤害。
说庆幸,是因为它开阔了我的视野,拔高了人生的短板。
说失望,是公司终究还是走上了不归路,原因不详,因为早已离职。以后我会详细说一下p2p老板跑路之后。太多人性的东西。
感谢这个公司里给过我帮助以及让我成长起来的人,这个公司最值得我感谢的就是夏菲(公司技术总监)。我要感谢他是因为他教会了我三件事:一、你自己的事情不管想什么办法都去把它去做好;二、产品的价值在于所做东西的细节;三、人的眼界决定人生的不同。
这些东西,在我以后的生活中给了我极大的帮助。
严格来说,真正的开发是从这里开始的,但实际上,这个公司并没有完整的开发流程和开发团队。没有产品,没有测试,美工也没有真正做过产品的美工,只有运营的一个简单的概念。说实话,做出来的东西用我现在的眼光来看,我不能说它是产品,只能算是一个试验品。可惜终究也没有线上去实验。
说到这里,我真的是不得不说一下,我为什么那么渴望云南的政府能有点作为了。我走过成都,漂过北京。10年前的成都,与昆明相差无几。而今来看,昆明差成都的不止一星半点。我是真心希望自己的家乡能够好一点。╮(╯▽╰)╭
时代造就了多少为了生存而背井离乡的人,为了生存,我走进了成都。成都陌云科技还是很有潜力的。每家公司都不可避免的存在一些问题,有些问题,或许是公司故意不去解决的。作为一名普通员工,我祝福这家公司能够越走越远。技术在这里得到了极大的提升。亦师亦友的小蒲,装x可亲的老王,探索人生的顾问(HR),一丝不苟的曾大姐。总之,陌云科技欢乐多。只要你能把本职工作干好,与人多一点沟通。在这个公司,欢乐大于悲桑!
说实话,我是不愿离开陌云的,再怎么落魄,而立之年,很多事情应该去做了,比如说:先要一个小孩。我不知道公司有没有过想留下我的想法。再说自己也很累了,想回家歇息一下。仓皇之间选择了北京圆心科技,多少带着些无奈。前面说过,第一家公司让我增长了见识,可是,我自己也把身价投进去了。老板跑路发生在请假回家这段时间。”辛辛苦苦几十年,一觉回到解放前”形容这个时候的我最恰当不过了。
在公司呆了大半年,我不知道公司的发展方向是什么。负责的也不是主要业务。但不管什么时候,都不会忘记学习这件事情,也许,只有学习能使我快乐了吧!
前面我们大致了解了下C语言中的字符串其实就是字符组成的数组,那么,要弄明白字符串,看来是不得不搞清楚数组了,还是看例子先:1234567891011121314#include <stdio.h>#include <stdlib.h>#include <string.h> void main(){ int a[10]; int *p1 = a; void *p2 = &a; int *p3 = &a[0]; printf("p1:%d----p1+1:%d\n",p1,p1+1); printf("p2:%d----p2+1:%d\n",p2,p2+1); printf("&a:%d----&a+1:%d\n",&a,&a+1); printf("p3:%d----p3+1:%d\n",p3,p3+1);}
以上代码输出结果:
1234p1:-1175211504—-p1+1:-1175211500 p2:-1175211504—-p2+1:-1175211503 &a:-1175211504—-&a+1:-1175211464 p3:-1175211504—-p3+1:-1175211500
观察p1和p1+1的,发现,p1+1比p1大4,也就是p1+1,指针p1移动了4个字节。
观察p2和p2+1的,发现,p2+1比p2大4,也就是p1+1,指针p1移动了1个字节。
观察&a和&a+1的,发现,&a+1比&a大4,也就是&a+1,指针&a移动了40个字节。
观察p3和p3+1的,发现,p3+1比p3大4,也就是p3+1,指针p3移动了4个字节。
结论: 1、数组名等效于数组的首元素取地址,即,对于数组a[10],在写代码时,a与&a[0]是等效的。 2、&a步长为40,代表指针偏移了整个数组那么长,因为整个数组所占的字节数为40; 3、p2与&a分别+1结果的不同,说明了,指针运算中的步长偏移量与指针所指向的内存空间的类型有关。第8行,由于强制规定了指针为void * 型,所以步长变成了1. 4、指针是一种数据类型,在不进行强制转换的情况下,指针的数据类型与他所指向的内存空间的数据类型一致。
