记一次mysql统计数据的优化过程
目标控制器:
http://xxxx.com/data/index (内部网站,不便透露地址)
缓慢原因分析:
网站优化,大多时候瓶颈都是出在mysql的查询上,特别是对于一些复杂的统计,当数据量大起来之后,各种连表,串库查询,更是如此。
所以,不用看代码,首先就来开启mysql的慢查询日志,果真发现了好几天查询巨慢的日志。慢sql如下:
注意sql中着重的部分,该部分ids非常多,有差不多至少5000多个。真实的查询时间为:# Query_time: 38.5
总的数据量为: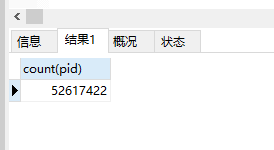
表结构:
用explain查看一下扫表行数和索引使用情况,发现扫表行数为:132032行。索引使用了rpid索引。
本sql主要的查询过滤条件为 reply_userid 因为这个字段用了5K之多的ids进行in查询操作。而从业务上分析,这个in操作又是不得不进行的。所以一开始,我把索引重心全都放到了reply_userid字段上。
而本查询刚好也用上了reply_userid。所以我放弃了对改sql索引方面的优化。转而进行从业务上进行修正。
业务熟悉:
从业务上看,本次操作的目的是:
1、从A库中的a表读取满足条件的用户,并取得这些用户的ids。
2、将拿到的ids到B库中的b表进行条件筛选。得到最终结果,再进行数据组装。
经过对业务的深入考察,初步出了两个方案。
方案一:(调整业务查询顺序)
由于步骤1查询到的数据量过大,再放入步骤2中查询,才导致查询过慢,那么如果可以把in查询中的ids数量减少,查询不就变快了吗?
所以,我想到的方案1是,先到B库中查询符合条件的数据。再把这些数据拿到A库中进行过滤,并得到最终结果。
方案二:
建一张统计表,按日统计数据,在符合条件的数据修改的接口处,把统计的数据汇总的统计表中,这是架构中最常规的做法,但是由于现在数据量已经上来了,系统涉及到的地方很多,这样做修改起来耗费的人力物力很多。所以该方案放到终极备用方案里面。
接下来就按照方案一的思路进行优化,发现效果并不明显,因为在第一步的操作中,虽然去除了in操作,但是其它字段也没用上索引啊!于是我考虑新建索引。我考虑到 posttime timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ‘回复时间’,
这一字段,发现每次筛选如果带上时间的话,再以这个时间为主,建立一个索引的话,可能速度会快上许多!因为索引的原理是在磁盘上按照建立的索引进行排序,把字段按顺序存储好。In查询之所以慢,是因为in里面的ids都是分散的,导致扫描的表会很多。而=,>,<操作不一样,是连续的。
但是,谁建的表:
时间不是应该用int型吗?常识!!!
我给大家看一下,为什么不要用timestamp,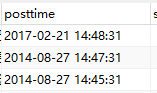
timestamp虽然底层也是整型,但是导致程序在进行查询的时候很麻烦,一般的程序员即使知道这里需要建立索引,他的程序也用不上。
看看我们原来是怎么做的。
这是最终的sql语句,
and unix_timestamp(p.posttime) >= 1485878400
and unix_timestamp(p.posttime) < 1487692800
这是原程序,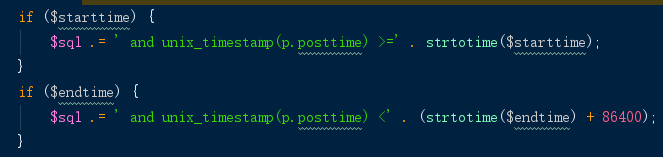
朋友们,看到了吗?
先把日期转换成时间戳,再跟mysql里面的字段进行对比,但是,mysql里imestamp类型的是日期格式的,所以也需要用内置函数unix_timestamp进行转换,结果,结果就是,我建了一万个索引,但是一个也没用上。
好了,说改就改,把程序对应的地方全部换成字符串日期格式,进行查询。对应sql是:
p.posttime >= 2017-02-14 18:19:23 and p.posttime < 2017-02-21 18:19:23
刷新页面,我靠,很遗憾!激动人心的时刻并没有到来。
报错了,sql语句错误,好吧,把sql复制到命令行直接执行,发现出错的地方主要是2017-02-14 18:19:23这个地方,我明白了,字符串加单引号的问题。
好了,怎么加单引号呢?
看php代码:
很简单,转义就好了。
写到这里,再吐槽一下,为毛时间字段的设计有的地方又是int型呢?导致我改也得一个地方一个地方对照表看准了才能改啊!哥们,下次php程序设计模型的时候,时间字段请统一用int!谢谢!
改到后面,发现,方案一中原来没预料到的问题暴露出来了,什么问题呢?
1是分页问题;
2是逻辑修改的复杂程度。
所以,我决定git checkout回原来的代码,还是先走下原来的逻辑。
好了,随后的事情就是优化了下原来的代码结构,把冗余的代码剔除。
最后,我决定再加点料。综合所有与该表有关的查询,建立一个大家都用得上的组合索引。
KEY posttime (posttime,rpid,status,reply_userid) USING BTREE
这就是最后建好的索引,测试一下,好了,原来的38秒变成了现在的0.4秒,虽然从explain的结果上看,还没有优化到最优,因为还用了文件排序和临时表。
但是由于我们并没有冗余统计字段,所以,该部分已经没法进一步优化。
==============================我是华丽的分割线============================
#开启mysql的慢查询日志的方法:
###1、 登录mysql;
###2、 show variables like “%slow%”;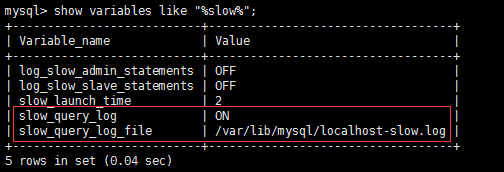
我的慢查询已经开启,慢查询日志位置为:/var/lib/mysql/localhost-slow.log
